
NoteThis version of the package was tagged as v.0.0.3 in the project repository, and can be examined there if desired. This post will cover only part of the changes in that version, with the balance in the next post.
The next layer in from the module-members testing discussed in the
previous article is focused on testing that the members identified there
have all of the expected test-methods. As noted there, this
testing-layer is concerned with callable members: functions and
classes, specifically. Beyond the fact that they are both callable
types, there are significant differences, which is why the wrappers for
testing functions and classes were broken out into the two classes that
were stubbed out earlier: the ExaminesSourceClass and
ExaminesSourceFunction classes.
The fundamental difference that has to be accounted for that led to
those two classes being defined is in how those member-types
are called, and what happens when they are called. In the case
of a function, the resulting output is completely arbitrary, at least
from the standpoint of testing. A function accepts some collection of
arguments, defined by its signature parameters, does whatever it’s going
to do with those, and returns something, even if that return value is
None.
A class, on the other hand, is always expected to return an instance of the class — an object — when it is called. That instance will have its own members, which are equally arbitrary, but can include both methods (which are essentially functions) and properties. It’s important to note that these properties have code behind them that make them work — they are a specific type of built-in data descriptor type, with methods that are automatically recognized and called by the Python interpreter when a get, set, or delete operation is called against the property or descriptor of a given object.
Class attributes, without any backing logic or code, fall into the same sort of testing category that module attributes do, also noted in a previous article. Specifically, while it’s absolutely functionally possible to test a class attribute, that attribute is, by definition, mutable: There is nothing preventing user code from altering or even deleting a class attribute, or that attribute as it is accessed through a class instance. Since the primary focus of the PACT testing idea is testing the contracts of test-targets, and attributes are as mutable as they are, they really cannot be considered as “contract” elements of a class.
After thinking all of those factors through, I decided that my next
step, the first new code that would be added to this version of the
package, would be focused on testing functions. The main
thought behind that decision is that establishing both the rule-sets and
implementation patterns for function-test requirements would provide
most of the rules and implementation patterns for class-members as well:
Methods of classes are just functions with an expected scope argument
(self or cls), and properties and other data
descriptor implementations are just classes with a known set of methods.
On top of that, functions implicitly have contracts, represented by
their input parameters and output expectations, so accounting for those
in defining the test-expectations for functions would carry over to
methods and properties later.
The test-expectations that I landed on after thinking through all of that boiled down to:
Goal
- Every function should have a corresponding happy-paths test method, testing all permutations of a rational set of arguments across the parameters of the function.
- Every function should also have a corresponding unhappy-path test-method for each parameter.
The goals for each of these test-expectations are still similar to the goals for test-expectations in previous versions’ tests: To assert that a given, expected test-entities exist for each source-entity. Because functions have their own child entities — the parameters that they expect — those expectations need to account for those parameter variations in some manner. My choice of these two was based on a couple of basic ideas: The happy-path test for a given function is, ultimately, intended to prove that the function is behaving as expected when it is called in an expected fashion. I fully expect that happy-path tests might be fairly long, testing a complete, rational subset of “good” parameter values across all of the logical permutations that a given function will accept. I do not expect that happy-path tests would need to be (or benefit from being) broken out into separate tests for each general permutation-type, though.
The unhappy-path tests, to my thinking, should build on the happy-path test processes as much as possible. Specifically, I’m intending that each unhappy-path test will use a happy-path argument-set as a starting-point for its input to the target function, but replace one of the arguments with a “bad” value for each rational type or value that can be considered “bad.”
An example seems apropos here, since I haven’t been able to come up with a more concise way to describe my intentions without resorting to code. Consider the following function:
def send_email(address: str, message: str, *attachments: dict):
"""
Sends an email message.
Parameters:
-----------
address : str
The address to send the message to
message : str
The message to send. May be empty.
attachments : dict
A collection of attachment specs, providing a
header-name (typically "Content-Disposition")
and value ("attachment"), a filename (str, or
tuple with encoding specifications), and a
file pointer to the actual file to be attached.
"""
# How this function actually works is not relevant
# at this point
...The happy-path test-method for this function,
test_send_email_happy_paths, would be expected to call the
send_email function with both a general email address and a
“mailbox” variant (john.smith@test.com and
John Smith <john.smith@test.com>), with both an empty
message, and a non-empty one, and with zero, one, and two
attachments arguments. That’s a dozen variations, but they
should be relatively easy to iterate through, even if they have to be
split out in the test-code, whether for readability, or to check that
some helper function was called because of circumstances for a given
call to the target function (for example, an attachment-handler
sub-process).
The unhappy-path tests, and what they use for their arguments break out in more detail based on which “unhappy” scenario they are intended to test:
test_send_email_bad_addresswould be expected to test for invalid email address values, and possibly for non-string types if there was type-checking involved in the processing for them, but could use the samemessageandattachmentsvalues for each of those checks.test_send_email_bad_messagecould use the sameaddressandattachmentsvalues, since it would be concerned with testing the value and/or type of some invalidmessagearguments.test_send_email_bad_attachmentscould use any validaddressandmessagevalues, as it would be testing for invalidattachmentselements.
As with the test-expectations established in previous versions, the
test-process for functions is only concerned with asserting that all of
the expected test-methods exist. That is a hard requirement
that’s implemented by application of the pact testing
mix-ins. The intention behind that is to promote implementation of
test-methods when possible/necessary, or to promote them being
actively skipped, with documentation as to the reason
why it is being skipped. That’s worth calling out, I think:
WarningThe
pactprocesses do not prevent a developer from creating an expected test-method that simply passes. That risk should be mitigated by application of some basic testing discipline, or by establishing a standard for tests that are not implemented!
Using the send_email function as an example, and
actively skipping tests for various reasons with the
unittest.skip decorator, the test-case class might
initially look something like this, after implementing the happy-paths
tests that were deemed more important:
class test_send_email(unittest.TestCase, ExaminesSourceFunction):
"""Tests the send_email function"""
def test_send_email_happy_paths(self):
"""Testing send_email happy paths"""
# Actual test-code omitted here for brevity
@unittest.skip('Not implemented, not a priority yet')
def test_send_email_bad_address(self):
"""Testing send_email with bad address values"""
self.fail(
'test_send_email.test_send_email_bad_address '
'was initially skipped, but needs to be '
'implemented now.'
)
@unittest.skip('Not implemented, not a priority yet')
def test_send_email_bad_message(self):
"""Testing send_email with bad message values"""
self.fail(
'test_send_email.test_send_email_bad_message '
'was initially skipped, but needs to be '
'implemented now.'
)
@unittest.skip('Not implemented, not a priority yet')
def test_send_email_bad_attachments(self):
"""Testing send_email with bad attachments values"""
self.fail(
'test_send_email.test_send_email_bad_attachments'
'was initially skipped, but needs to be '
'implemented now.'
)This approach keeps the expected tests defined, but they will be
skipped, and if that skip decorator is removed, they will
immediately start to fail. Since the skip decorator
requires a reason to be provided, and that reason will appear in test
outputs, there is an active record in the test-code itself of
why those tests have been skipped, and they will appear in the
test logs/output every time the test-suite is run.
That covers what the goal is, in some detail. The implementation,
how it works is similar, in many respects, to other test-case
mix-ins already in the package from previous versions. For function
testing, the new code was all put in place in the
ExaminesSourceFunction class that was stubbed out in
v.0.0.2. With the implementation worked out, that class’
members can be diagrammed like this:

As with previous mix-ins, the entire process starts with the
test-method that the mix-in provides,
test_source_function_has_expected_test_methods, and the
process breaks out as:
test_source_function_has_expected_test_methodscompares its collection ofexpected_test_entitiesagainst the actualtest_entitiescollection, causing a test failure if any expected test-methods in the first do not exist in the second.- The
expected_test_entitiescollection is built using thetarget_functionto retrieve the name of the function and its parameters, along with theTEST_PREFIX,HAPPY_SUFFIXandINVALID_SUFFIXclass attributes, which provide thetest_prefix for each method, the happy-path suffix for that test-method, and invalid-parameter suffixes for each parameter in thetarget_functionparameter-set. - The
target_functionis retrieved using the name specified in theTARGET_FUNCTIONclass attribute, finding that function in thetarget_module, which is imported using the namespace identified in theTARGET_MODULEclass-attribute. - The
test_entitiesmethod-name set is simply retrieved from the class, using theTEST_PREFIXto assist in filtering those members.
Many of the defaults for the various class attributes have already
been discussed in previous posts about earlier versions of the package.
The new ones, specific to the ExaminesSourceFunction class
are shown in the class diagram for the package at this point:
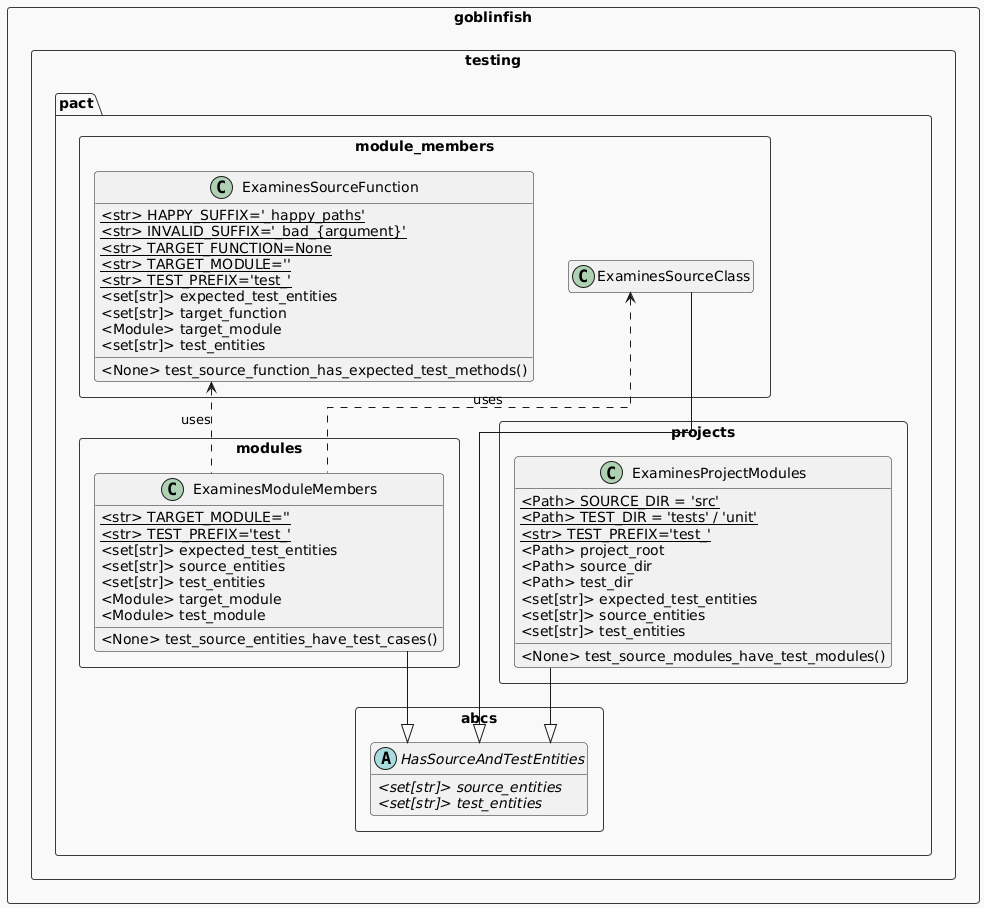
- The
HAPPY_SUFFIX, used to indicate a happy-paths test-method, defaults to'_happy_paths'; - The
INVALID_SUFFIX, is used to append a'_bad_{argument}'value to unhappy-path test-methods, where the{argument}is replaced with the name of the parameter for that test-method. For example, theaddress,message, andattachmentsparameters/arguments noted earlier in the example for thesend_emailfunction. - The
TARGET_FUNCTIONprovides the name of the function being tested, which is used to retrieve it from thetarget_module, which behaves in the same fashion as the property by the same name in theExaminesModuleMembersmix-in fromv.0.0.2.
When v.0.0.2 was complete, the example project and its
tests ended up like this:
project-name/
├─ Pipfile
├─ Pipfile.lock
├─ .env
├─ src/
│ └─ my_package/
│ └─ module.py
│ ├─ ::MyClass
│ └─ ::my_function()
└─ tests/
└─ unit/
└─ test_my_package/
├─ test_project_test_modules_exist.py
│ └─ ::test_ProjectTestModulesExist
└─ test_module.py
├─ ::test_MyClass
└─ ::test_my_function
With a bare-bones my_function implementation like
this:
def my_function():
pass…running the test_my_function test-case class, or the
entire test-suite, immediately starts reporting a missing
test-method:
================================================================
FAIL: test_source_function_has_expected_test_methods
...
[Verifying that test_my_function.test_my_function_happy_paths
exists as a test-method]
----------------------------------------------------------------
...
AssertionError: False is not true :
Missing expected test-method - test_my_function_happy_paths
----------------------------------------------------------------
Adding the required test-method, being sure to use the skip-and-fail pattern shown earlier, like this:
class test_my_function(unittest.TestCase, ExaminesSourceFunction):
TARGET_MODULE='my_package.module'
TARGET_FUNCTION='my_function'
@unittest.skip('Not yet implemented')
def test_my_function_happy_paths(self):
self.fail(
'test_my_function.test_my_function_happy_paths '
'was initially skipped, but needs to be implemented now.'
)…allows the test-case to run successfully, skipping that test-method in the process, and reporting the reason for the skip, provided that the test-run is sufficiently verbose:
test_my_function_happy_paths
(test_my_function.test_my_function_happy_paths)
skipped 'Not yet implemented'
If the function is altered, adding a positional argument, an argument-list, a keyword-only argument, and a typical keyword-arguments parameter, like so:
def my_function(arg, *args, kwonlyarg, **kwargs):
pass…then the test-expectations pick up the new parameters, and raise new test failures, one for each:
================================================================
FAIL: test_source_function_has_expected_test_methods
...
[Verifying that test_my_function.test_my_function_bad_args
exists as a test-method]
...
----------------------------------------------------------------
...
AssertionError: False is not true :
Missing expected test-method - test_my_function_bad_args
...
================================================================
...
[Verifying that test_my_function.test_my_function_bad_kwonlyarg
exists as a test-method]
...
----------------------------------------------------------------
...
AssertionError: False is not true :
Missing expected test-method - test_my_function_bad_kwonlyarg
...
================================================================
...
[Verifying that test_my_function.test_my_function_bad_kwargs
exists as a test-method]
...
----------------------------------------------------------------
...
AssertionError: False is not true :
Missing expected test-method - test_my_function_bad_kwargs
...
================================================================
...
[Verifying that test_my_function.test_my_function_bad_arg
exists as a test-method]
...
----------------------------------------------------------------
...
AssertionError: False is not true :
Missing expected test-method - test_my_function_bad_arg
...
----------------------------------------------------------------
Adding those expected test-methods, unsurprisingly, allows the tests to pass, reporting on the skipped test-methods in the same manner as shown earlier:
class test_my_function(unittest.TestCase, ExaminesSourceFunction):
TARGET_MODULE='my_package.module'
TARGET_FUNCTION='my_function'
@unittest.skip('Not yet implemented')
def test_my_function_bad_arg(self):
self.fail(
'test_my_function.test_my_function_bad_arg '
'was initially skipped, but needs to be '
'implemented now.'
)
@unittest.skip('Not yet implemented')
def test_my_function_bad_args(self):
self.fail(
'test_my_function.test_my_function_bad_args '
'was initially skipped, but needs to be '
'implemented now.'
)
@unittest.skip('Not yet implemented')
def test_my_function_bad_kwargs(self):
self.fail(
'test_my_function.test_my_function_bad_kwargs '
'was initially skipped, but needs to be '
'implemented now.'
)
@unittest.skip('Not yet implemented')
def test_my_function_bad_kwonlyarg(self):
self.fail(
'test_my_function.test_my_function_bad_kwonlyarg '
'was initially skipped, but needs to be '
'implemented now.'
)
@unittest.skip('Not yet implemented')
def test_my_function_happy_paths(self):
self.fail(
'test_my_function.test_my_function_happy_paths '
'was initially skipped, but needs to be '
'implemented now.'
)test_my_function_bad_arg
(test_my_function.test_my_function_bad_arg)
skipped 'Not yet implemented'
test_my_function_bad_args
(test_my_function.test_my_function_bad_args)
skipped 'Not yet implemented'
test_my_function_bad_kwargs
(test_my_function.test_my_function_bad_kwargs)
skipped 'Not yet implemented'
test_my_function_bad_kwonlyarg
(test_my_function.test_my_function_bad_kwonlyarg)
skipped 'Not yet implemented'
test_my_function_happy_paths
(test_my_function.test_my_function_happy_paths)
skipped 'Not yet implemented'
After these additions, this example project looks like this:
project-name/
├─ Pipfile
├─ Pipfile.lock
├─ .env
├─ src/
│ └─ my_package/
│ └─ module.py
│ ├─ ::MyClass
│ └─ ::my_function(arg, *args, kwonlyarg, **kwargs)
└─ tests/
└─ unit/
└─ test_my_package/
├─ test_project_test_modules_exist.py
│ └─ ::test_ProjectTestModulesExist
└─ test_module.py
├─ ::test_MyClass
└─ ::test_my_function
├─ ::test_my_function_bad_arg
├─ ::test_my_function_bad_args
├─ ::test_my_function_bad_kwargs
├─ ::test_my_function_bad_kwonlyarg
└─ ::test_my_function_happy_paths
While the equivalent test-processes for class-members still needs to
be implemented, there are already significant gains at this point in
prescribing tests for functions. The fact that all of the types of
class-members that an active contract testing process really needs to
care about are, themselves, just variations of functions means that the
processes implemented for function-testing will at least provide a
baseline for implementing class-member test expectations. They may even
use the exact same code and processes. That said, this post is long
enough already, so the implementation and discussion of the class-member
pact processes will wait until the next post.





